
Estou iniciando a tradução de uma série de tutoriais referente a Mineração de Dados escritos pelo Daniel Calbimonte, clique AQUI para acompanhar, apesar de entender que a língua padrão utilizada na área de tecnologia é o inglês, mas sei que muita gente tem dificuldade em entender ou até mesmo encontrar material sobre muitos assuntos. No entanto os comandos ou conceitos de Banco de Dados não serão traduzidos tais como “select, where, procedure, trigger, view, etc”, além disso os nomes das colunas também não ser traduzidos, também vou utilizar a versão do Microsoft SQL Server Data Tools – Business Intelligence for Visual Studio 2012 ao invés do BIDS 2008 R2, clique AQUI para fazer download.
Let´s go !!! 😉
Na antiguidade clássica o oráculo era considerado como a fonte de conselhos e profecia ou predição do futuro, inspirado pelos deuses. Eles ganhavam uma oferenda para que pudessem predizer o futuro e aconselhar sobre seus desejos. Hoje nós não temos mais os oráculos para predizer o futuro. Seria bom termos um oráculo para predizer como nossos negócios estão indo ou quanto vamos ganhar nos próximos dois anos e a outras questões relacionadas ao futuro.
Uma vez que não temos oráculos (pelo menos nenhum bom), a mineração de dados foi criada para nos ajudar a analisar nossas informações e prever o futuro.
Mineração de Dados
A mineração de dados é o processo de descobrir padrões e um conjunto grande de dados. Um sistema especialista usa a experiencia histórica (armazenada em bancos de dados relacionais ou cubos) para predizer o futuro. Deixe-me explicar o que você pode fazer com mineração de dados usando um exemplo.
Imagine que você é proprietário de uma companhia chamada AdventureWorks. Essa companhia vende e fabrica bicicletas. Você quer prever se um cliente vai comprar ou não uma bicicleta com base nas informações do cliente. Como você pode cumprir a missão ?
A resposta é Mineração de Dados. Esta ferramenta que encontra padrões e descreve as características dos clientes que possuem a maior probabilidade ou a menor probabilidade de comprar bicicletas. A Microsoft tem uma ferramenta boa incluída no SQL Server Analysis Services. Você não precisa criar um cubo ou um projeto do analysis service. Você pode trabalhar diretamente com os bancos de dados relacionais.
Exemplo
Nesse exemplo, nós vamos trabalhar com o banco de dados AdventureWorksDW, se você não tem instalado, você pode fazer o download a partir do site http://msftdbprodsamples.codeplex.com.
Uma vez que tenha instalado o AdventureWorksDW, use o select para verificar a informação na view v_targetmail.
SELECT * FROM vTargetMail
Se você revisar o resultado, você vai encontrar muitas informações sobre o que os consumidores gostam:
- The customer key
- The title
- The age
- Birthdate
- Name
- Lastname
- MaritalStatus
- Suffix
- Gender
- EmailAddress
- YearlyIncome
- TotalChildren
- NumberChildrenAtHome
- EnglishEducation
- SpanishEducation
- FrenchEducation
- EnglishOccupation
- SpanishOccupation
- FrenchOccupation
- HouseOwnerFlag
- NumberCarsOwned
- AddressLine1
- AddressLine2
- Phone
- DateFirstPurchase
- CommuteDistance
- Region
- Age
- BikeBuyer
Todas as informações são importantes, mas são muitas. Como você pode encontrar padrões ? Por exemplo, se uma pessoa é casada, (a coluna maritalstatus) pode afetar a decisão de comprar uma bicicleta. A idade é muito importante também, dependendo da idade da pessoa pode ou não comprar uma bicicleta. Como você sabe qual coluna é importante ? Qual característica tem maior impacto na decisão de comprar uma bicicleta ?
Como você pode perceber, é muito difícil encontrar qual atributo afeta a decisão por causa das 32 colunas da tabela. São muitas combinações, e é muito difícil encontrar padrões. Se você criar um cubo com todas as informações, é mais fácil encontrar padrões mas mesmo com os cubos, podemos perder alguns padrões por causa das diferentes combinações.
Por isso nós usamos Mineração de Dados. Para organizar todas as colunas, analisá-las e priorizá-las.
Note que existe uma coluna chamada bikebuyer (ultima coluna). Essa coluna exibe o valor 1 para o cliente que comprou a bicicleta ou 0 para quem não comprou. Esse valor é o que procuramos prever. Queremos saber se um cliente vai comprar ou não bicicletas com base em nossa experiência (nesse caso a experiência é a view vTargetMail).
Começando
Nesse exemplo, eu vou mostrar como criar um Projeto de Mineração de Dados usando a view vTargetMail.
Existem 3 sessões aqui.
- Criar o Data Source (Fonte de Dados)
- Criar o Data View (Visualização de Dados)
- Criar o Projeto do Data Mining
- Predizer a informação usando o Modelo de Mineração
Criando o Datasource
Primeiro vamos selecionar o servidor do SQL Server e as propriedades da conexão. Isso é o Data Source.
1. Para inicializar o Projeto do Data Mining nós vamos usar o SQL Server Business Intelligence incluído na Instalação do SQL Server.

2. Vá em Arquivo > Novo Projeto a selecione um projeto do Analysis Services

3. A direita do Explorador de Soluções , clique com o botão direito em Fonte de Dados.

4. No Assistente da Fonte de Dados clique em avançar.

5. Nós vamos criar uma nova conexão com a fonte de dados, clique em novo.

6. No gerenciador de conexões especifique o nome do servidor

7. No assistente de Data Source, selecione avançar.

8. Pressione Avançar e Finalizar.
Você criou a fonte de dados para o banco de dados AdventureWorksDW.
Criando a exibição da fonte de dados
Agora vamos adicionar a view vTargetMail a fim de adicioná-la vamos usar a fonte de dados que criamos. Para retornar o Data Source View vamos adicionar as tabelas e a view ao projeto.
1. No Solution Explorer, clique com o botão direito em Data Source View e selecione New Data Source View.
2. Clique em next na tela de boas vindas do Data Source View Wizard.

3. Na janela a segui, selecione uma fonte de dados, nesse caso vamos selecionar a fonte de dados que criamos.

4. Em Select Tables and Views, selecione a vTargetMail e pressione o botão >
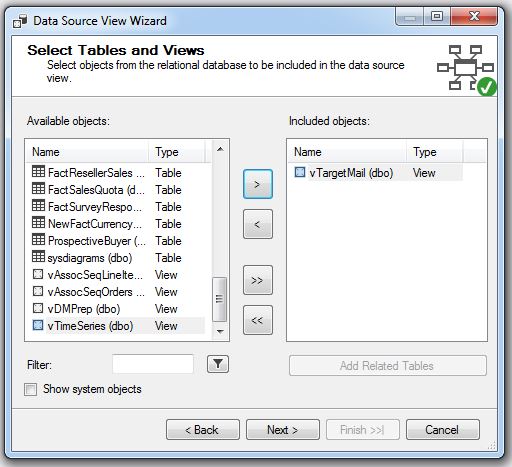
5. Complete a janela do Assistente e pressione Finish.
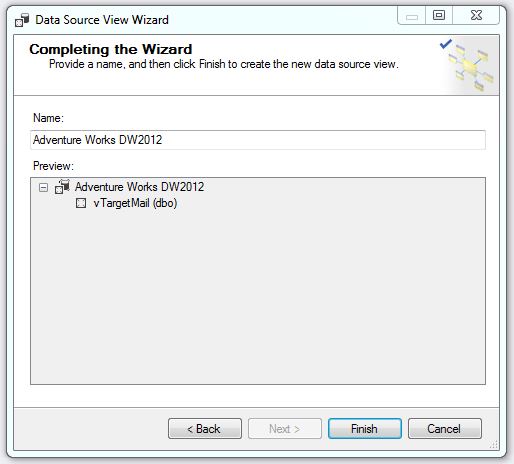
Nós apenas criamos um Data View com o objetivo de dar experiencia para nosso Modelo de Mineração de Dados. O vTargetMail é uma view que contem os dados históricos dos consumidores. Usando essa experiencia, nosso modelo de mineração poderá prever o futuro.
Modelo de Mineração de Dados
Agora vamos criar o Modelo de Mineração usando o Data Source e o data Source View foram criados anteriormente.
1. No Solution Explorer, clique com o botão direito em Mining Structures e selecione New Mining Structure.
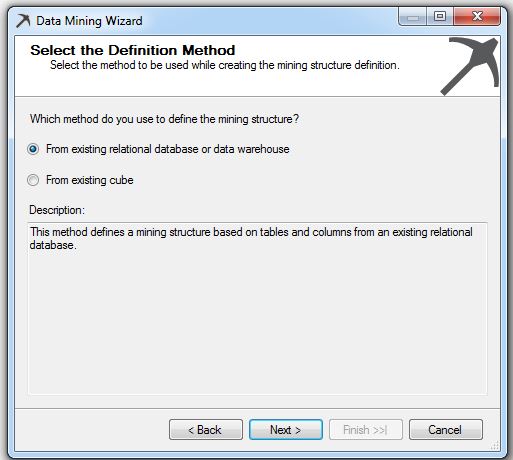
2. Na tela de boas vindas do assistente de Data Mining, pressione next.

3. Em Select the Definition Method, selecione a opção “from existing relational database or data warehouse” e clique em next, como você pode ver podemos usar Bancos de Dados relacionais, data warehouse ou cubos.
4. Em “Create the Data Mining Structure Window”, selecione a opção “Create mining structure with a mining model” e selecione “Microsoft Decision Trees e pressione avançar. Eu vou explicar em detalhes em outro artigo sobre as técnicas de mineração. Até o momento vamos usar o algorítimo Árvore de Decisão para esse exemplo.

5. Em “Select Data Source View”, selecione o Data Source View que foi criado e clique em avançar.
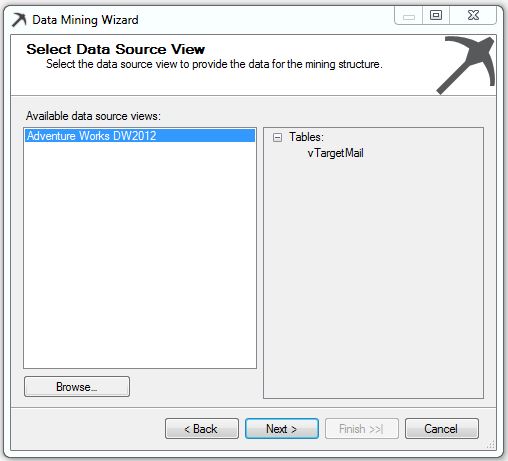
6. Em “Specify Table Types” selecione vTargetMail
7. Em “Specify the Training Data”, na linha Bike Buyer, marque o check box na coluna Predict e pressione o botão Suggest. Nesta opção estamos selecionando as informações que vamos prever. Neste cenário queremos prever se a pessoa é ou não um comprador de bicicleta.

8. Marque a coluna input com um x em todos os nomes onde a pontuação é diferente de 0. O que estamos fazendo é escolher quais colunas são relevantes para a decisão de comprar uma bicicleta.

9. Na coluna da esquerda, selecione “first name, last name e e-mail” isso vai ser usado para fazer o drill through e pressione next.

10. Em “Specify Columns Content and Data Type”, pressione Detected e pressione next. Eu vou explicar sobre os tipos de conteúdo em um futuro artigo. Neste momento, vamos detectar os Data Types

11. Em “Create Testing Set”, estipule o valor de 100 no campo “Maximum number of cases in testing data set” e pressione avançar.
Essa janela é usada para testes de dados. Eu vou explicar com mais detalhes em um futuro artigo.

12. Em “Completing the Wizard”, escreva o nome da estrutura de mineração e o nome do modelo de mineração e marque a opção “drill though” e pressione Finish.

13. Agora clique em Mining Model Viewer
![]()
e você vai receber uma mensagem do Windows para realizar o Deploy do projeto, clique no botão Yes.

14. Nós vamos receber a mensagem para processar o Model, pressione Yes.

15. Em Process Mining Model, clique em Run

16. Na árvore de Processo, uma vez que tenha concluído com exito clique em close.

16-1. Esse tópico não está na versão original.
Pode acontecer de ocorrer erro no processamento por conta de permissão de usuário, para resolver isso existem diversas maneiras, uma elas eu vou ensinar aqui.

No SQL Server, crie um usuário com permissão de leitura no AdventureWorksDW2012, não é necessário mais nenhuma outra permissão para esse usuário, após isso
Em Data Sources, dê um duplo clique em Adventure Works DW2012.ds

Em seguida clique em Edit e altere a opção de “Log on to the server” para “Use SQL Server Authentication” e insira o usuário que foi criado no SQL Server com acesso a base do Adventure WorksDW2012

Em seguida no Solution Explorer, clique com o botão direito em cima da “Mining Structures” que foi criada chamada de DTStructure e selecione a opção Process e execute novamente a partir do passo 14.
17. Clique em Mining Model Viewer. A árvore de decisão vai ser exibida.

Nós acabamos de criar um projeto de Data Mining usando Árvore de Decisão. Ele está pronto para testar. Nossa tarefa final é usa-lo. Vou criar algumas consultas para prever se um usuário vai comprar ou não uma bicicleta usando o Data Mining.
Prevendo o futuro
Agora que temos nosso Data Mining, vamos perguntar ao nosso Oráculo se um cliente com características específicas vão comprar ou não bicicletas.
A primeira consulta, vai pedir ao nosso Oráculo se um cliente de 45 anos, com uma distancia de 5-10 milhas, com ensino médio vai comprar uma bicicleta. A segunda consulta vai pedir ao nosso Oráculo, se um cliente de 65 anos com uma distancia de 1-2 milhas sem estudo tem vontade de uma moto.
1. Primeiro nós precisamos clicar na aba Mining Model Prediction.

2. Na janela Mining Model Window, clique em Select Model
3. Na janela Select Mining Model, expanda o Data Mining > DTStructure e selecione o DTModel e clique em OK

4. Em Select Input Table, clique em Select Case Table

5. Na janela Select Table, selecione o vTargetMail e pressione OK.

6. Clique com o botão direito na janela Select Input Table e selecione Singleton Query

7. Na consulta do Singleton especifique as seguintes informações.
Age 45: Commnute Distance 5-10 Miles, English Education: High School, English Ocupation: Professional, Marital Status: S, Numerber of Cars Ownerd: 5, Number of children at home: 3
Nesse passo, você deve especificar as características do consumidor.
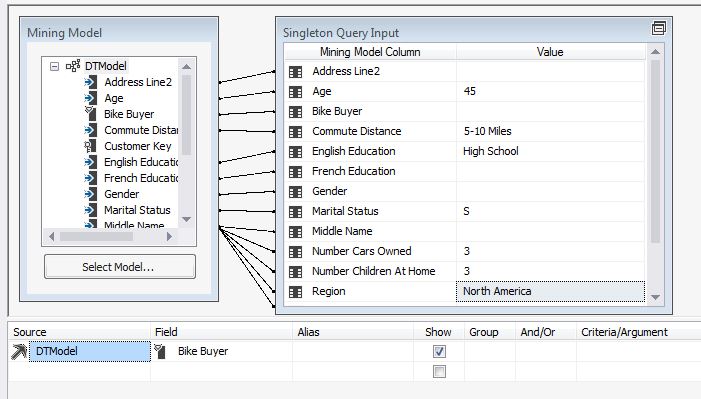
8. No combobox, selecione DTModel Mining model.

9. Na segunda linha, selecione a coluna source, clique no combobox e selectione “Prediction Function”.
10. Na segunda linha, a coluna Field , selecione PredictHistogram
11. Na coluna Criteria/Argument escreva [DTModel].[Bike Buyer], o que estamos fazendo agora é especificar a probabilidade de que este usuário venha a comprar uma bicicleta usando o PredicHistogram
12. Agora clique no icone e selecione Result para verificar os resultados da consulta.

13. Se você observar o resultado você vai perceber que a probabilidade de comprar uma moto é de 0,437. Isso significa 43%. Portanto, agora temos o nosso Oráculo pronto para prever o futuro !

14. Finalmente vamos perguntar se outro consumidor com as seguintes características vai comprar uma bicicleta.
Age 65: Commnute Distance 1-2 Miles, English Education: Missing, English Ocupation: Clerical, Marital Status: S, Numerber of Cars Ownerd: 1, Number of children at home: 0. In this step we are specifying the customer characteristics.

15. Uma vez feito isso, vamos selecionar novamente a opção do Result.

A probabilidade de um consumidor comprar com essas características é de 38%
Resumo
Este artigo nos descreve como prever o futuro usando Data Mining. São muitos cenários para aplicar Data Mining. Esse é um exemplo que usamos o algoritimo da Árvore de Decisão para prever o futuro.
Nós usamos a View para popular nossos Modelo de Mineração e nós perguntamos ao modelo se 3 clientes comprariam nossas bicicletas. O primeiro teve uma probabilidade de 43% e no segundo 38%.
Agora que você tem o seu modelo de mineração de dados pronto, pode lhe perguntar o futuro.
Boa sorte.
Referencias.
http://nocreceenlosarboles.blogspot.com/2011/11/al-oraculo-de-delfos-no-le-dejan-votar.html
http://msdn.microsoft.com/en-us/library/ms167167(v=sql.105).aspx

Muito boa a iniciativa, vou acompanhar todos. Parabéns.
Obrigado Alessandro.. 😉
Como faço para instalar o banco de dados AdventureWorksDW no SQL Server Business Intelligence ???
Olá,
Você pode baixar pelo site https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0 e depois realizar o processo normal de restore.